Ready or Not: AI Deep Researchers are Coming for Your Unstructured Data

- Type: Product Insights
- Date: 03/06/2025
- Author: Alistair Jones
- Tags: Data Governance, Data Access Governance (DAG), AI Readiness
The journey towards the AI Enterprise has accelerated dramatically with the widespread adoption of generative AI tools like Microsoft Copilot. Employees have quickly found meaningful value in using these tools, particularly for capturing meeting notes, document summaries and as email-writing partners.
However, new capabilities are on the horizon for our enterprise AI assistants. They’ll be smarter than ever, because they’ll be accessing more of your enterprise’s files and documents than ever before. And with that, enterprises must now confront a new reality: these AI agents will soon access internal data in ways that pose significant security risks. Are you prepared?
Whether you are a Data Governance Officer or Information Security Team Leader, this blog post is going to cover what to expect in the near-term future of AI assistants and AI agents, and how to get ready.
Cutting Through the AI Assistant Hype
Let’s take a minute to understand the state of hype-free Enterprise AI and consider the trajectory we are on. First, a point of order: There are plenty of applications for AI in the enterprise but what this blog post is focused on are the LLM-based Enterprise AI products that are built for the average knowledge worker — tools like Microsoft 365 Copilot or Gemini. These are the broadest and most widely relevant AI products to all kinds of different job functions and that thousands of employees will interact with on a daily basis.
In the 2023 Gartner Microsoft 365 Survey of IT Leaders, over 80% of respondents indicated that Copilot was in the top three most valuable new features in M365.
This success was largely based on use cases around summarization, taking meeting notes, drafting documents, etc, but the real value is connecting these agents with more data so that they can produce better output.
Given the day-to-day activities of the office worker, the most relevant information will be in written communication, such as agendas, memos, reports, emails, messages, event descriptions and so on — data that is both private to an enterprise and unstructured in nature. According to the vision outlined in talks by CEOs of Microsoft, Google and OpenAI, being able to do this exceptionally well is the bar that the industry leading AI labs have set for themselves..
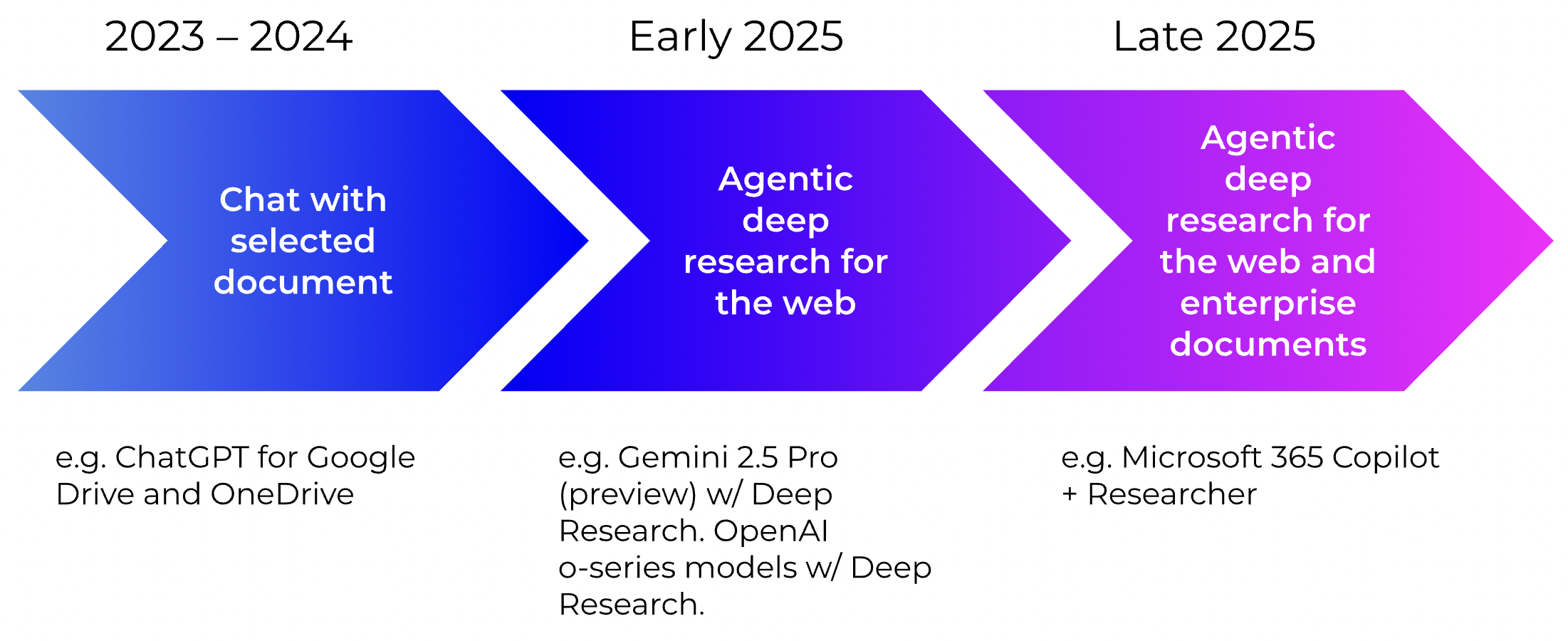
The first wave of LLM models and knowledge worker AI Assistants in 2023 and 2024, to be perfectly honest, fell short of that bar. Chat-with-your-documents style assistants are in the middle of slow careful rollout, with “select & upload documents” user experience designs, instead of “search my documents and understand what is relevant for me”.
Rather than retrieval of multiple documents, the leading AI labs instead have been focusing on the more essential task of trying to understand the content of a single document better. This is already a monumentally difficult task, for example parsing a complicated table, understanding abstract graphs of business processes or describing a photo or screenshot in a document are all required to be able to do this well. And in terms of usefulness and priorities, there’s no point in retrieving a relevant set of documents if you can’t understand what’s inside a single one.
Examining the state of the industry on the relevant retrieval front, Microsoft Copilot was perhaps ahead of the curve with some limited document retrieval features here, allowing a user to casually refer to documents by name or other high-level metadata fields, but these weren’t the cross-application “business chat” style agents where a user can give it a high-level big picture query and let the agent run with a query until it is complete.
Deep Research Rollout
Late last year, the capabilities of AI leapt forward when reasoning models began to emerge from the frontier labs. What’s so different about this batch? Well two big things:
- First, they talk to themselves, evaluate their own output, and determine if they actually answered the question that they were asked and if not, they try again.
- Second, they are fine-tuned for tool use like search APIs.
If you combine these two capabilities, you have a new tier of assistance that wasn’t possible before.
This is how the emerging deep research or deep reasoning AI products differ fundamentally: they search, self-assess the response, correct their queries, and repeat, dramatically improving their ability to find and retrieve relevant documents. After consulting a wide range of sources, they consolidate that information into easily consumable comparison tables.
In my own usage, I’m using deep research requests dozens of times a week. And they show real promise and value — a feat that’s not too common at this stage of the frothy hype cycle.
There’s a catch (for now).
Deep Researchers are much better at semi-structured documents, like a webpage, and not quite there for unstructured documents like PDFs, etc. It’s beyond the scope of this blog to outline the difference in the scale of the challenge between the two, but suffice it to say that websites have common structures and standards that make them more parsable. This is quite obvious when you consider the rollout of these features: Deep Research AI only search the web and never enterprise documents.
If you follow the announcements close enough, you can read between the lines and see that the Deep Researchers are still struggling with enterprise documents. All of the leading AI labs know this. Look no further than the limitations and qualifiers that come attached to these state-of-the-art Deep Researchers.
Google Gemini 2.5 Pro with deep reasoning was released months ago, but still has a stubborn “preview” label associated with it. Google most recently announced at Google I/O that you can now manually select and upload documents to Gemini 2.5 Pro (Preview) in deep reasoning mode, which is an unfortunate workaround to them not being able to solve the retrieval problem.
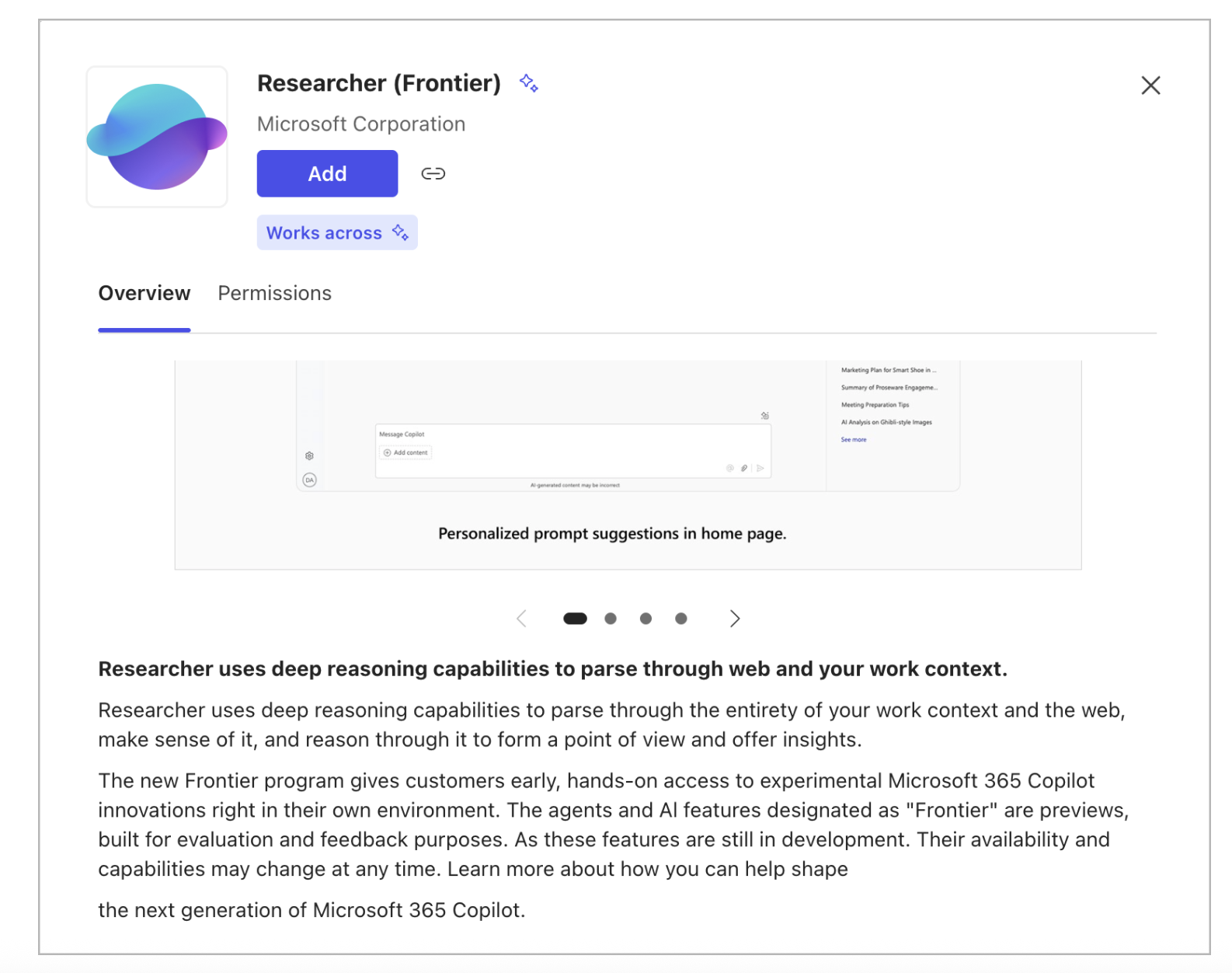
The best-in-class AI agent is Microsoft 365 Copilot with the “Researcher” agent. Like its spreadsheet-specialized agent “Analyst”, Microsoft packages Researcher behind a “frontier” label.
If you are a Microsoft 365 user, you can enable it in the nice new agent store, but you’ll note that Microsoft dedicates two-thirds of its description warning you that it is “early”, “experimental,” a “preview”, and still “in development”. In short, it’s not finished yet.
The output from these labs shows a trajectory that indicates one thing: the deep researchers will be here for the SharePoints and OneDrives soon. Already in their current forms, limited to websites, these products are impressive achievements. The slow rollouts of SharePoint and enterprise integrations are necessary and consciously designed to gather feedback from the market to refine both the models and the product experience of using them on the documents.
So how is this impacting your average enterprise user? And how is this going to impact security and compliance teams running the show?
Data Access Rot vs. the Deep Researchers
Here’s a conservative scenario for the future of the Microsoft enterprise: With your most adventurous employees turning on the preview versions of the Researcher (Frontier) agent now, by the end of the year, let's say a majority of your employees will have their own tireless, data-hungry, AI-powered researchers that will consult hundreds of documents for which it has permission to do so per query. If there is a document accessible to AI researchers, consider that it will be found and used by them by the end of the year.

How well are your enterprise’s file permissions suited for the task of laying down the right boundaries? Consider that file in your OneDrive from a few years ago that has an open-access link still active for it. Or perhaps some employee evaluation interview notes for a job hiring process that you shared with your fellow interviewers at the time. Teams grow, roles change, employees leave, but the file permission settings are more rigid than our ever evolving enterprise. There’s data access rot in our SharePoints and OneDrives. These files have always been a liability but many of them go unnoticed. The deep researchers will have no problem noticing them.
It's essential to ensure documents have proper boundaries—clearly defined file entitlements that restrict document access strictly to those who need it. This tactical step not only delivers immediate benefits by sharply reducing the risk of inadvertent exposure but also lays a robust foundation for your broader AI-readiness strategy. Establishing precise entitlement management is Data Access Governance (DAG) and it ensures you’re prepared for the future by proactively limiting oversharing risks.
At Ohalo, we’ve been sounding the alarm bells over the newfound importance of DAG, and we aren’t alone. We were quite pleased when we read Gartner’s 2024 Strategic Roadmap for World-Class Security of Unstructured Data which backs up our concerns.
In their report, their recommendations were simple and straightforward:
- enterprises will need to invest in dedicated unstructured data classification tooling to enable AI use cases like Copilot rollouts and beyond, and
- prioritizing DAG to “rightsize entitlements for generative AI yields immediate return”.
We find this particularly compelling because focusing on ROI for unstructured data scanning, while anchoring it in a winning strategic roadmap that unlocks deeper value is our MO at Ohalo.
Data X-Ray: Data Access Governance Made Easy
Enter Data X-Ray, our industry-leading unstructured data intelligence platform, perfectly suited to handle this two-fold approach. Data X-Ray delivers rapid, on-premises scanning across complex environments, accurately classifying vast amounts of data at extraordinary speeds. Through leveraging advanced generative AI, it offers unparalleled contextual insights, categorizing documents according to their precise security needs.
Deploying Data X-Ray immediately highlights your most vulnerable sensitive data—data that is currently unprotected or inadequately secured. For example, we collect metadata on each file like entitlements and open-share links for Sharepoint and OneDrive. Generating a straightforward CSV output, IT teams can swiftly pinpoint and lock down sensitive files, instantly reducing risk exposure. This quick win is not just an easy exercise but a critical step that yields immediate returns and sets a solid foundation for your deeper, longer-term AI and data security strategy.
As enterprises grapple with the complexities of AI readiness, adopting a solution that swiftly addresses immediate data security concerns is indispensable for the coming deep researchers. Starting with Data X-Ray and performing a DAG initiative positions organizations not just to mitigate current threats, but also to build a resilient, secure, and future-ready data environment.
In short, achieving AI readiness is indeed challenging, but choosing the right starting point with DAG through Data X-Ray ensures you're on a clear and confident path toward harnessing the full power of AI safely and securely.
Don’t wait until sensitive data leaks become critical issues. Contact us for a demo today, rapidly identify, classify, and secure your unstructured data, immediately mitigating risks and preparing your enterprise to confidently embrace next-generation AI assistants.”
