
Enterprise data classification in Microsoft Purview

- Type: Product Insights
- Date: 06/03/2025
- Author: Alistair Jones
- Tags: Data Governance, Data protection, data security, data discovery
At Ohalo, we are fans of Microsoft Purview. It has a deep integration with Microsoft 365 and capabilities that allow it to scan other cloud platforms like AWS. However, there are limitations that are only obvious after an in-depth tour of the tool. Without proper awareness of some of the constraints, we’ve seen enterprise initiatives to implement Purview grind to a halt after multi-year efforts. Any Microsoft Purview implementation plan should begin with an in-depth understanding of the challenges that data and security teams will encounter.
This blog post shares concrete results of what sensitive data scans actually look like in Purview. We will create simple test files that should have predictable results and show how sensitive data detection can vary wildly depending on where the document is hosted.
Keep it Simple: An Exercise in Classification
Let’s start with a simple task to get our bearings: detecting credit card information inside a document. Any sensitive scanning tool should be able to breeze through a task like this. However, it’s not completely straightforward either, as there is more variety and more constraints to credit card formats than one might think.
- All credit cards start with a first digit identifier, e.g., 4 for Visa and 5 for Mastercard, etc., and this will never be 0.
- Credit card numbers must pass the Luhn validation, which prevents users from making off-by-one errors in their calculations.
- They commonly have 16-digit or 19-digit formats, but some issuers will have valid 14- or 15-digit formats as well.
- Different formats have different display formats by convention, like XXXX XXXX XXXX XXXX for 16 digits and XXXX XXXXXX XXXXX for 15 digits.
- The separation delimiter in the format is done with a whitespace character and hyphens.
- For some use cases, there may even be legacy formats that are rare but still possible to find.
Most of these requirements in pattern matching credit cards are fixed, but others can depend on the use cases and systems that are scanning. For example, if we are scanning archival or legacy systems, old credit card formats may be appropriate. But keep in mind that there is no one solution even for this, and there’s no replacement for learning your tool.
File 1: Card Number Card Type Account Holder Expiry Date Obsolete Format 4477 7176 089 30157 VISA John Rambo 08/23 N 4807072103141723048 VISA James Braddock 01/22 N 4276646120248 VISA Paul Kersey 10/25 Y 2250502505305720 Mastercard John Matrix 08/23 N 2256040864667970 Mastercard Ah Jong 01/22 N 5252 3311 6927 2575 Mastercard Beatrix Kiddo 10/25 N 3759 199385 19665 AMEX Henry Jones Jr. 08/23 N 3785-702352-07913 AMEX Bob Plissken 01/22 N 349329612031818 AMEX John McClane 10/25 N 6595 9690 1942 1845 Discover Nico Toscani 08/23 N 6011 1234 5678 9012 348 Discover Max Rockatansky 01/22 N 6011234567890123 Discover Alex Murphy 10/25 N 3573735083095242 JCB JJ McQuade 08/23 N 3530 9006 4191 251 JCB Matt Hunter 01/22 Y 3572 2097 2202 6036 486 JCB Alan Schaefer 10/25 N 3630 7207 1431 96 Diners Club Nikolai Rachenko 08/23 Y 2598 4480 7164 3097 Diners Club Marion Cobretti 01/22 N 3696 7681 7889 8332 471 Diners Club Martin Riggs 10/25 N 6313 9336 4700 Maestro Hutch Mansell 08/23 Y 5602 3456 78906 Maestro Robert McCall 01/22 N 5082-3983-1711-248 Maestro Steven Hiller 08/23 N 6759 8765 4321 0986 Maestro Danny Roman 01/22 N 5649980127898771690 Maestro Chris Sabian 10/25 N 4844 6964 4022 9018 Visa Electron James Dial 08/23 N 4175 3303 6000 2436 884 Visa Electron Lenore St. John 10/25 N 6371 2345 6789 0127 InstaPayment Kate Macer 08/23 N
And what good is this test if we don’t also throw in some false positives? In a separate Excel spreadsheet, we will also add the following tests:
File 2: Card Number Card Type Card Type Expiry Date Comments 4111111111111112 Visa Evelyn Abbott 25-Jan Visa-like number with the last digit altered so it fails the Luhn check. 555555555555444 Mastercard Jane Smith 25-Nov Mastercard-like number with only 15 digits (incorrect length). 37828224631000X AMEX Samantha Caine 25-Sep AMEX-like number containing a non-digit character. 60111111111111117 Discover Charly Baltimore 25-Dec Discover-like number with an extra digit (17 digits total). 3530 1113 3330 000 JCB Alice Racine 25-Jul JCB-like number with mis-formatted whitespace leading to an incorrect digit count. 6759649826438452 Maestro Molly Stewart 25-May Maestro-like number with an incorrect check digit (one digit off Luhn). 0000000000000000 Visa Julie Hastings 25-May Common false positive by customer feedback 04477717608930137 N/A Rebecca Ryan 25-Dec Valid credit card that is prefixed with a 0, for testing word boundary checks 0447771760893013 N/A Steven Aught 25-Dec Can't start with a zero 48 07 07 21 03 14 17 23 04 8 Visa Lori Anderson 25-Nov No conventional formattings
Our goal here is simply to use these files to explore these tools. Whatever your classification tool of choice, we recommend using these two files to get oriented with how your tool’s classification system behaves.
Scanning an S3 Bucket
For this section, Purview’s Data Map Solution will be used to scan the above files. AWS S3 buckets were used for convenience and to test Purview’s impressive multi-cloud scanning capabilities. Purview has extensive documentation, including plenty of guidance on how to start scanning an S3 bucket. Although it is out of scope for this article, the process of setting up scanning credentials on AWS and adding an S3 bucket as a Purview source was generally found to be well done.
Time to prep the scan. In AWS, we created a new bucket and we added the documents to it so that these were the only two documents in the datasource. Over in Purview’s Data Mapping Solution, we created a new domain, and the S3 bucket was connected directly as a new datasource.
We are almost ready to start but first, we need to pick a ruleset. We are going to be using the system default for “AmazonS3”.
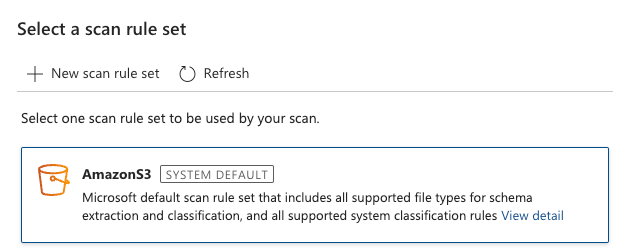
This is a good default because it will include the classification rules that are “Credit Card Number” and “EU Debit Card Number” and this kind of scan includes Microsoft Excel file types. Go ahead and start the scan.
5 minutes later, the results are in. For the credit card positive matches, we have the following report.
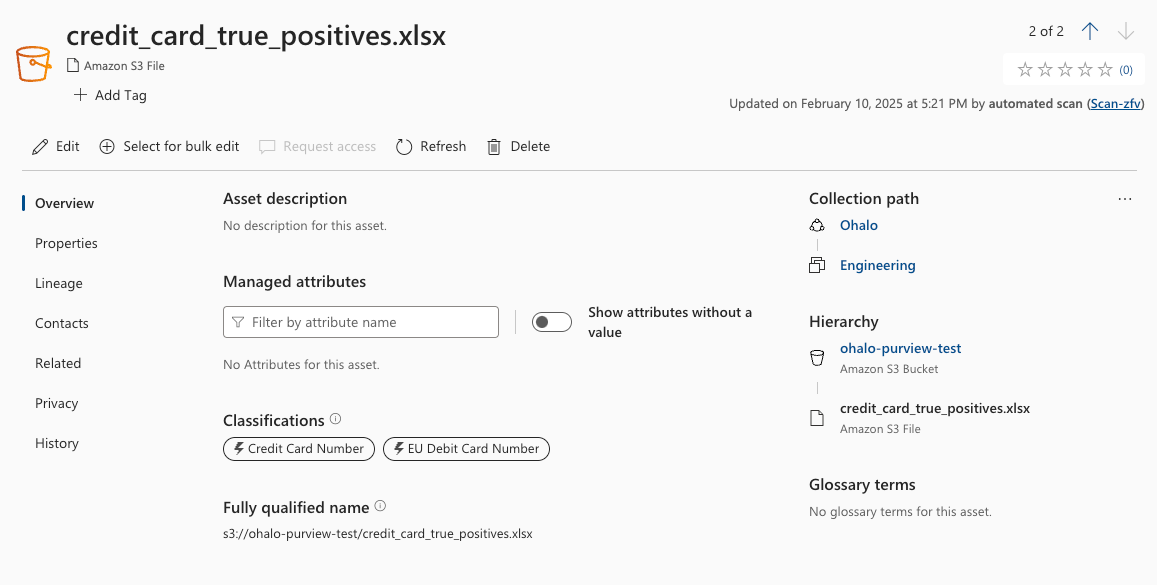
And for the true positive results, on hover we have additional information:
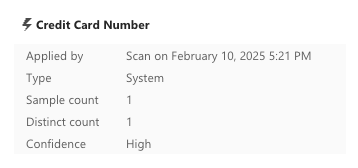
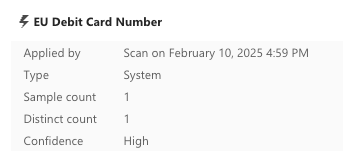
And the false positive test file:
The result is a mixed bag, ranging from good to very concerning.
First, the good news. Purview is reporting;
- credit_card_false_positives.xlsx has no false positives
- credit_card_true_positives.xlsx has the Credit Card Number classification and the EU Debit Card Number classification associated with it.
Now, the very concerning. Purview is reporting;
- credit_card_true_positives.xlsx has only one sample count of each of the Credit Card Number classification and the EU Debit Card Number classification.
From this first report of the tool, it’s clear that Purview has missed at least 20 other non-obsolete credit card number formats.
Why? The answer has to do with where the data is being hosted. To begin answering that question, consider how the results would have been if I scanned them in OneDrive.
Scanning a OneDrive
Because we are using a test Microsoft tenant with an E5 license, we had the wild idea of scanning the files again from a different datasource to confirm the results were the same. The same two files scanned with the same rules should produce the right same results, right? Right??
We uploaded the files to a OneDrive where they were automatically scanned using Microsoft Purview information Protection rules, which includes by default the Credit Card Number classification and the EU Debit Card Number classification.

Viewing the results of the scans requires extremely elevated levels of permissions and may not be available to everyone. Because we’ve granted ourselves full privileges in our test tenant, we can use the Purview “Content Explorer (classic)” view from the portal. Here, the files from all users were visible, including the two above, so we appreciate that this may not be available to you from your enterprise, and in our experience, we rarely see enterprises even granting this permission to anyone. The problem is that we found the information it provides to be essential to implementing a proper classification policy. But for now, we’ll post screenshots for your reference below.
However, if you are following along at home, ensure you have the right permission inside Purview for viewing this. Check the Microsoft Purview settings > “Roles and Scopes” > “Role Groups” and assign “Content Explorer List Viewer” and “Content Explorer Content Viewer” to your user. Note that these permissions are assigned inside Purview and not available in Azure Entra (more on that later).
Once you have access, the result is a nice in depth view of the actual file contents like this:
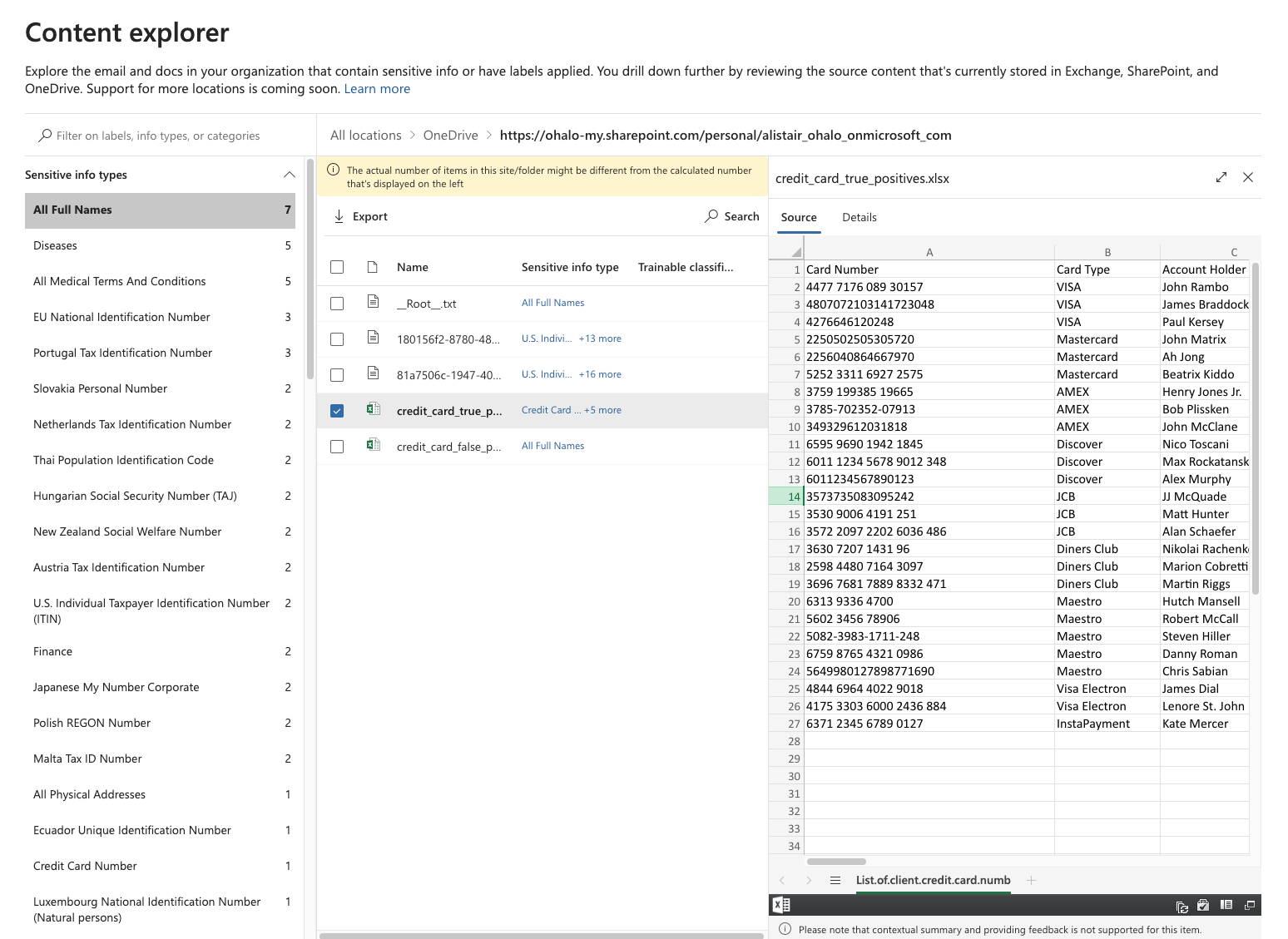
Even though it would be very helpful to see the credit card finding in the context within the file content, this level of visibility is welcomed (if not necessary for data protection professionals).
We can drill in to see just a bit more details.
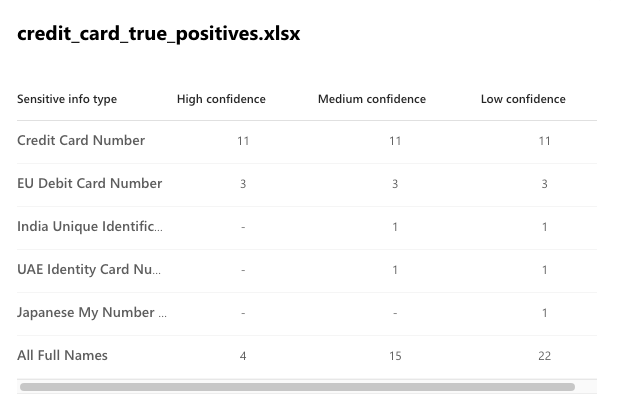

The results are also a mixed bag:
- Using the high confidence level, it has found 11 credit cards and 3 E.U. debits cards, without any false positives. This is great! But this means that there are another 8 non-obsolete credit card numbers that slipped through. 14 out of 22 credit cards found, for such an easy task, is not exactly a resounding success.
- We see that the “All Full Names” did a great job of actually capturing full names. Using the more noisy low confidence level, 22 out of 26 in the first file, and 10 out of 10 in the second is a solid result for a sensitive info type that does not follow a strict pattern.
But more importantly, why are they so different from the exact same files that we scanned previously? There are only two credit cards detected earlier and now there are 14. Moreover, full name scanning was actually also turned on for the first scan as well, and there were 0 results there. It’s almost as if there was something different happening behind the scenes depending on the data source you scan.
Two Different Scanning Engines Under the Hood
These results point to one possible explanation: there are two different classifications engines that are used depending on which datasource Purview is scanning. These engines belong to two separate Purview solutions:
- Microsoft Purview’s Data Map solution has a classification engine used to scan file server multi-cloud file servers, database, storage buckets, and websites
- Microsoft Purview‘s Information Protection solution has a classification engine used for Outlook, OneDrive, and Sharepoint
When you use Purview, you have to ensure you learn how to use both in order to get their true potential. This goes down to the level of the rules that are defined. First, take a look and how Credit Card Rules are defined differently across solutions:
- Microsoft Purview Data Map System Classification “Credit card number”
- Microsoft Purview Information Protection Sensitive Info Type (STI) “Credit card number”
You can note the rules are different. For example, the latter does detect 19-digit card numbers, while the former does not. Indeed, Information Protection rules are more modern and comprehensive.
Two sets of scanning rules is a big deal. Our main criticism of Purview is that it is incredibly easy to miss the distinction between the two engines. We assumed initially that we misread the documentation, but we found examples of Purview muddling the distinct scanning engines in their UI. Here, right on the Information Protection solution, they refer to the scanning capabilities of their second engine, which we feel they are referring to both “scans” as interchangeably similar. This can be misleading.
So how do you actually fix this? Essentially, if you want to make sure the files are the same you need to make sure all classification rules are the same across the two. You need to create custom rules, one set of patterns for the Data Map, and another set of patterns for the Information Protection.
As Information Protection rules are more modern than Data Map rules (at least based on Credit Card Number definitions), it could be good to recreate the STIs as classifications in a Data Map and keep the two in sync manually. Or just surrender to the messiness and keep two different definitions between Classification and STIs, but this will lead to serious constraints down the road depending on your organization's goals, particularly around unstructured data mapping and cataloging.
The problem is that you are left with having to use the common denominator across the two solutions, and that often comes down to writing regular expressions and word lists. If you take this approach, this means that you cannot use the best that Information Protection has to offer, notably:
- Trainable classifiers, which are file-level categorizers custom trained with 50-500 sample documents. But these don’t actually detect and annotate sensitive data inside the document so they have plenty of excellent use cases, but detecting credit cards is not one of them.
- Patterns, which are probably one of Purview’s greatest features, and essentially regular expressions and checksum validators with a compelling UX around them.
- EDM classifiers which are essentially a living glossary of sensitive words.
All these are great Information Protection solution features, but they are not present in the Data Map solution and they are not useful for any other datasources outside of OneDrive, Outlook and Sharepoint.
Data Map scanning is somewhat behind Information Protection in terms of feature parity. But they do have their own feature that is not present in Information Protection: regular expression suggestions. We hoped that this may take away some of the customization pain, so we decided to try it on the file above. We uploaded the Excel file from above as CSV.
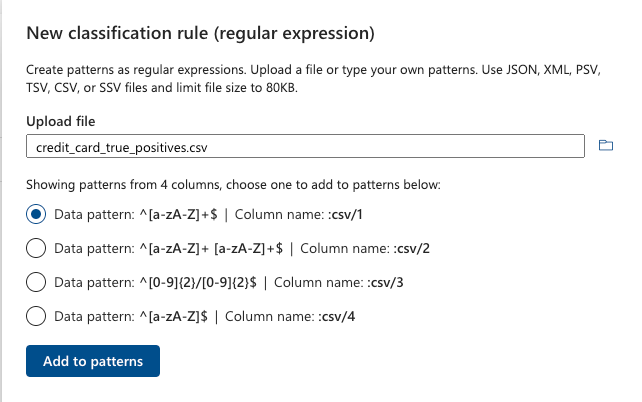
We cannot see anything in here that will usefully match a credit card in any way. You are better off having a conversation with your preferred AI chatbot and skipping this regular expression suggestion feature. LLM powered chatbots are typically great at drafting and explaining regular expressions, but still, once you have your rules defined, it’s important to test them out by rerunning this exercise again.
Finally, an astute reader will note that at this point, we haven’t exactly explained precisely why Data Map scanning finds only one sample of each classification. Or why it doesn’t find any Full Names even though these were active classification rules in the scan. Alas, more scanning and testing is required around schematized data asset scanning and how it relates to auto-policy labelling. This is functionality that is in preview, and has changed significantly already once when we started doing our research and evaluation of Microsoft Purview. This will be another blog post for another time, whenever we finally figure it out.
Other Snags
During our experimental run, we ran into a few issues but for the sake of brevity, we left them off the story above. We mention these in case you were to encounter them as well.
Cryptic error messages
Our first two scans of the Amazon S3 bucket did not actually successfully completeI downloaded a CSV file with an error log and I have obtained the following explanation.

This was resolved by recreating S3 bucket from scratch, which then scanned with no error.
Phantom assets
We wish we had an explanation for this one, but there, as you can see above, clearly two and only two items in the test S3 bucket. In the Data Map scan, Purview has “discovered” three, but only “classified” two.
We were unable to diagnose the cause of this or determine if it was intended behavior. More testing is required.
Classification overview
Another thing that we haven’t covered much here is that we have found Purview’s classification dashboard lacking. Though we were pleased with the Content Explorer (classic), this won’t be available for most data protection professionals due to permissions, leaving no great way to see scan results.
What we were missing most was a clear overview of how many classifications were found in each data source, as well as the abilities to easily search and filter over file types.
Purview permissioning is not Azure-based
As mentioned before, Purview has a set of very powerful access privileges that are only accessible within the Purview portal, and are not accessible as Microsoft Entra Roles or Groups. This can lead to some complications in user management and administration.
Not a blocker for implementing this in our test organization, but your organization may have strict issues with how accounts are managed. Commonly, enterprises require all credentials be managed through Azure, either through privileges or through groups, so consult with your procurement specialists if this is the case in your organization.
Preview means preview
There are many additional and interesting features that have the “preview” label in Microsoft Purview, like schematized data asset auto-labelling policies that can be configured from inside Microsoft Information Protection and applied to Microsoft Data Map. These are very much still a work in progress and we’ve been unable to properly evaluate them as they have already significantly changed since the start of doing our research and evaluation. The preview status could remain for a long time as they try to figure out best practices.
Our Recommendations
Stick to Purview’s regular expressions
If your organization has ambitions for unstructured data mapping projects beyond Outlook, Sharepoint and OneDrive, stick to regular expression in Purview.
Otherwise, be prepared to have serious discrepancies in rule coverage across your Data Map and Information Protection datasource scans.
Remember that scanning for the same rules on the same files will appear differently depending on what kind of datasource you are scanning. Now is a good time to evaluate whether or not Purview is right for your enterprise and your use case.
It may be enough, but there are limits to how you will be able to profit from a scanned datasource, unless you understand the differences between schematized asset data scanning and document-style scanning, and navigate appropriately.
Test thoroughly
Have a clear set of user acceptance test criteria, even for regular expressions, in order to make sure that your rules are working with you.
Our experiments here were more of an illustrative evaluation, but it has shown the need for designing your own rule sets and implementing your own more in depth accuracy metrics and test cases for capturing precision and recall.
Move methodically and carefully
Puview comprises two different automated classification systems working side by side: Data Map classification and Information Protection classification. The former was first designed for structured data, and is more recently being adapted to cover unstructured data. The latter was built with unstructured first and remains separate from the second. The double classification system approach becomes apparent when using the tool in earnest, one must carefully design a strategy around it.
Finally, reach out to us with your own experiences and successes with Purview. We’d love to hear about how you managed to achieve success with Purview or where we can help.
