
How Extractors Make Unstructured Data Instantly Valuable

- Type: Events
- Date: 24/07/2025
- Author: Kyle DuPont
- Tags: Data Governance, AI Readiness, Data Classification
70–90% of enterprise knowledge lives in documents you can’t query.
What if you could flip that into clean, usable, structured data, right where the files already live?
Unstructured data such as documents, PDFs, images, and content scattered across SharePoint, network drives, Box, and Google Drive make up the majority of your enterprise data. According to Gartner, it’s estimated to be 70–90% of all enterprise content.
But here’s the problem:
You can’t search it. You can’t analyze it. And you definitely can’t automate workflows with it.
That’s where Data X-Ray’s Extractors come in.
loading...

Before Extractors: The Cost of Doing Nothing
When it comes to documents, the “do nothing” path looks like this:
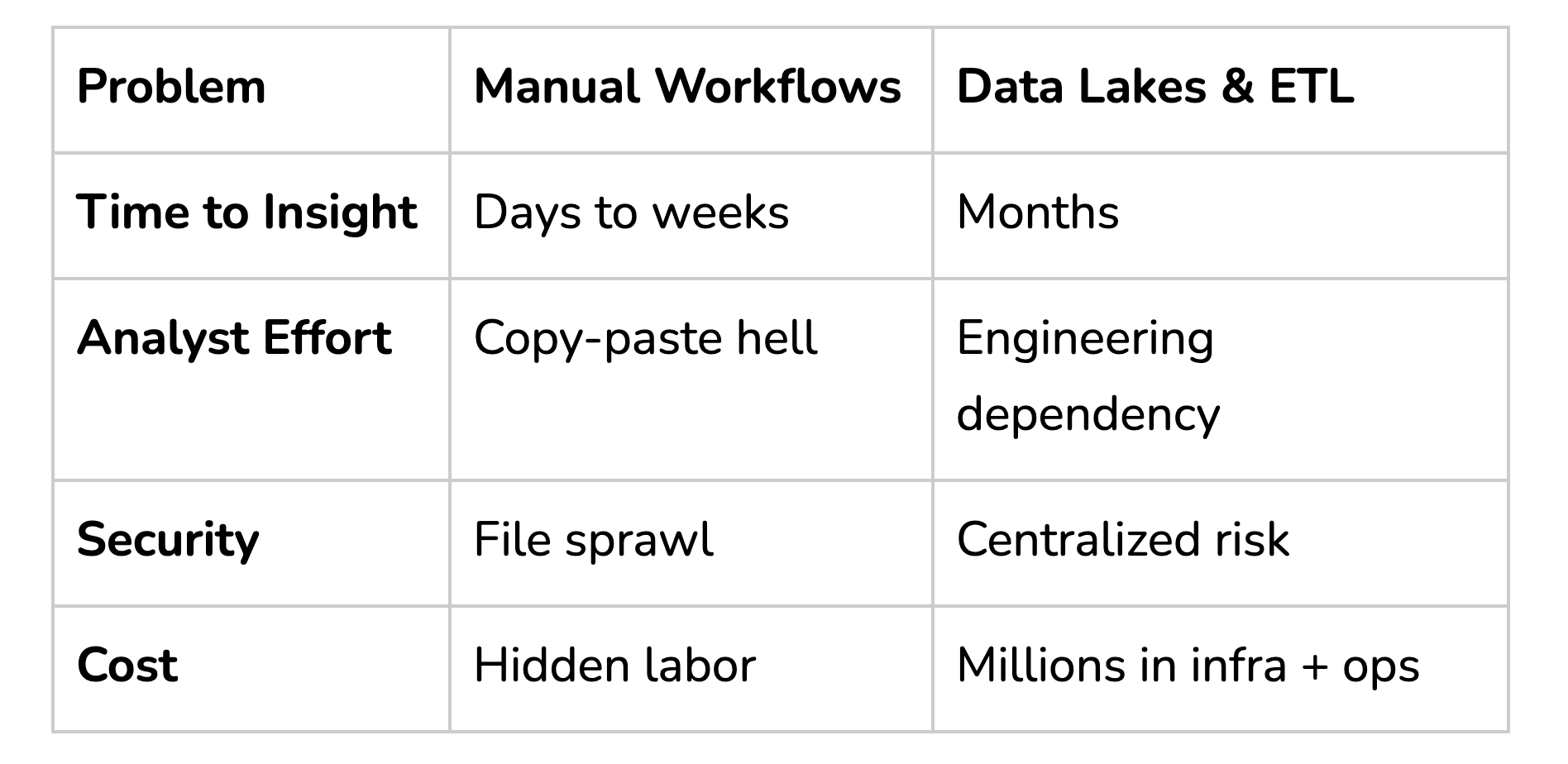
You’re either relying heavily on manual review or building expensive pipelines that move sensitive files around just to get insights.
The New Play: Treat Your Documents Like a Database
Forget centralizing or replatforming. Extractors let you ask questions of your documents and instantly get back structured answers:
Risk clauses from 10,000 contracts
Counterparties and durations from lease agreements
Customer IDs from invoice folders
Executive summaries from buried audit reports
That’s exactly what Data X-Ray Extractors let you do.
Using a simple in-app interface, you can define what to extract like dates, names, clauses, or tags, and run it directly on your content in situ.
Live Demo Example: From Credit Reports to Clean JSON
In the webinar, we showed how to extract key metadata from a credit risk report without moving a file:
Document: Credit_Assessment_FN1234.docx
Fields Extracted:
Report Date: 2023-10-15
Company Name: AlphaTech
Credit Score: 745
Revenue: 15M
Risk Summary: “Consistent revenue growth and effective cost management”
And it doesn’t stop there. The output is structured as searchable metadata, usable in workflows, analytics tools, or data catalogs like Collibra .
The Big Advantage: In Situ Extraction
Unlike traditional ETL or manual work, extractors:
Run directly on your SharePoint, Box, or Drive content
Require no replatforming, no pipelines, no engineer dependency
Respect existing entitlements (so access stays governed)
Output structured data like JSON, lists, booleans, or labels
This is metadata you can search, filter, label, route, and act on.
Use Cases Across the Org
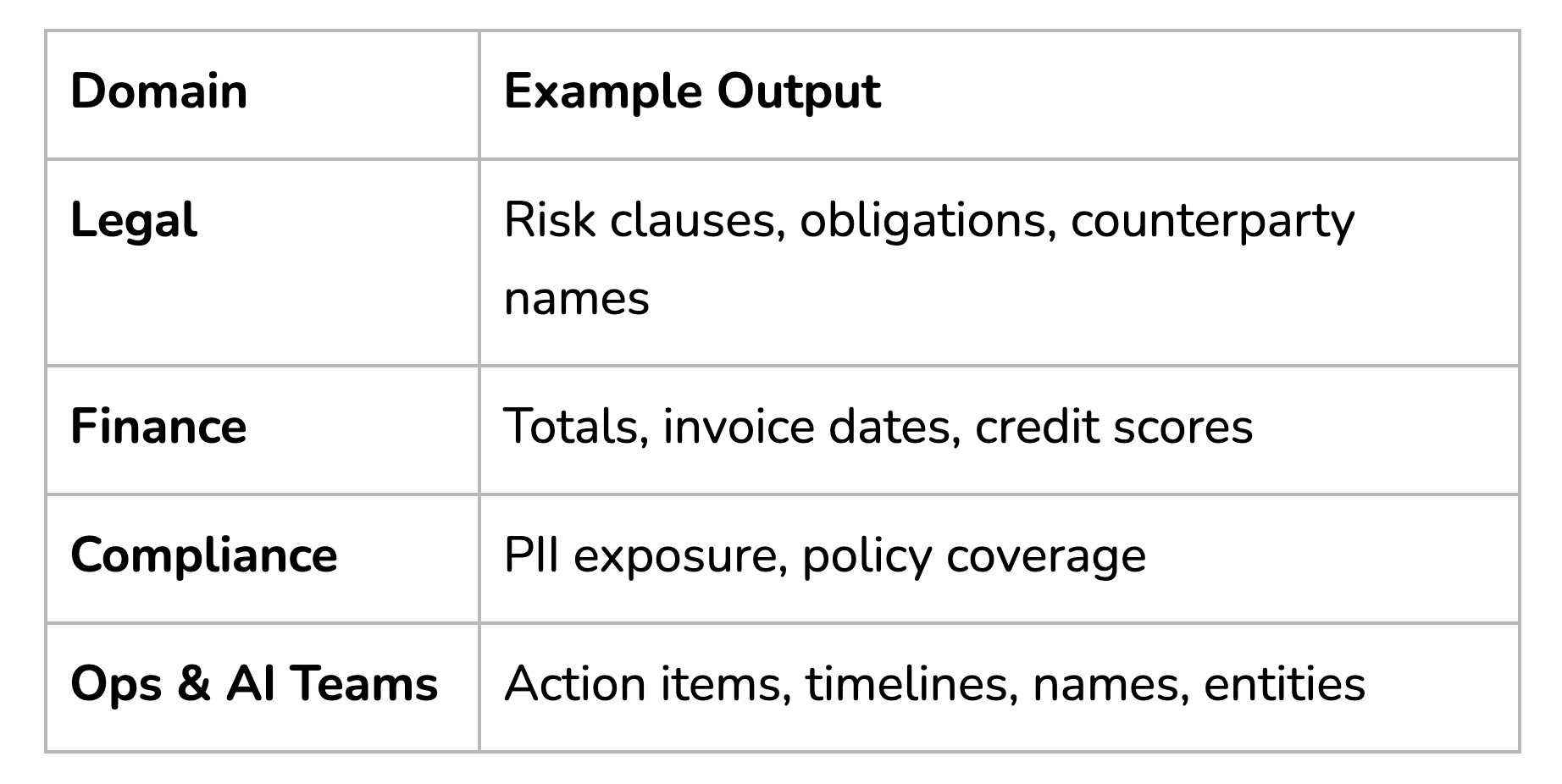
Whether you’re training an LLM, enforcing a DLP rule, or flagging gaps in vendor contracts, Extractors make it instant.
Data X-Ray Extractors: Why This Isn’t Just a Feature
This is a shift.
- From passive file storage → to intelligent metadata extraction
- From “data chaos” → to “searchable knowledge”
- From manual and slow → to automated and in-place
Book a Personalized Demo
See how Data X-Ray can help you extract value from your documents. No pipelines, no re-platforming.
